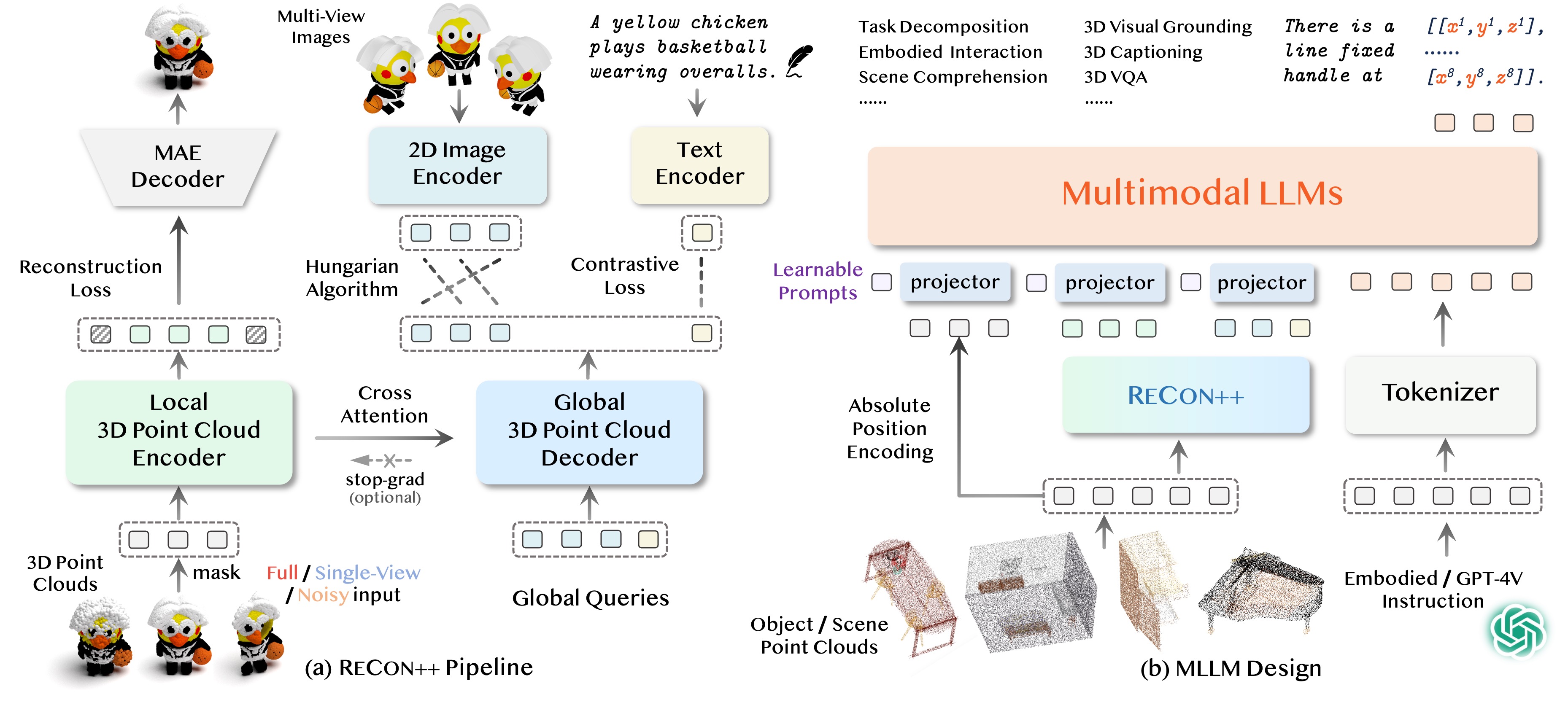
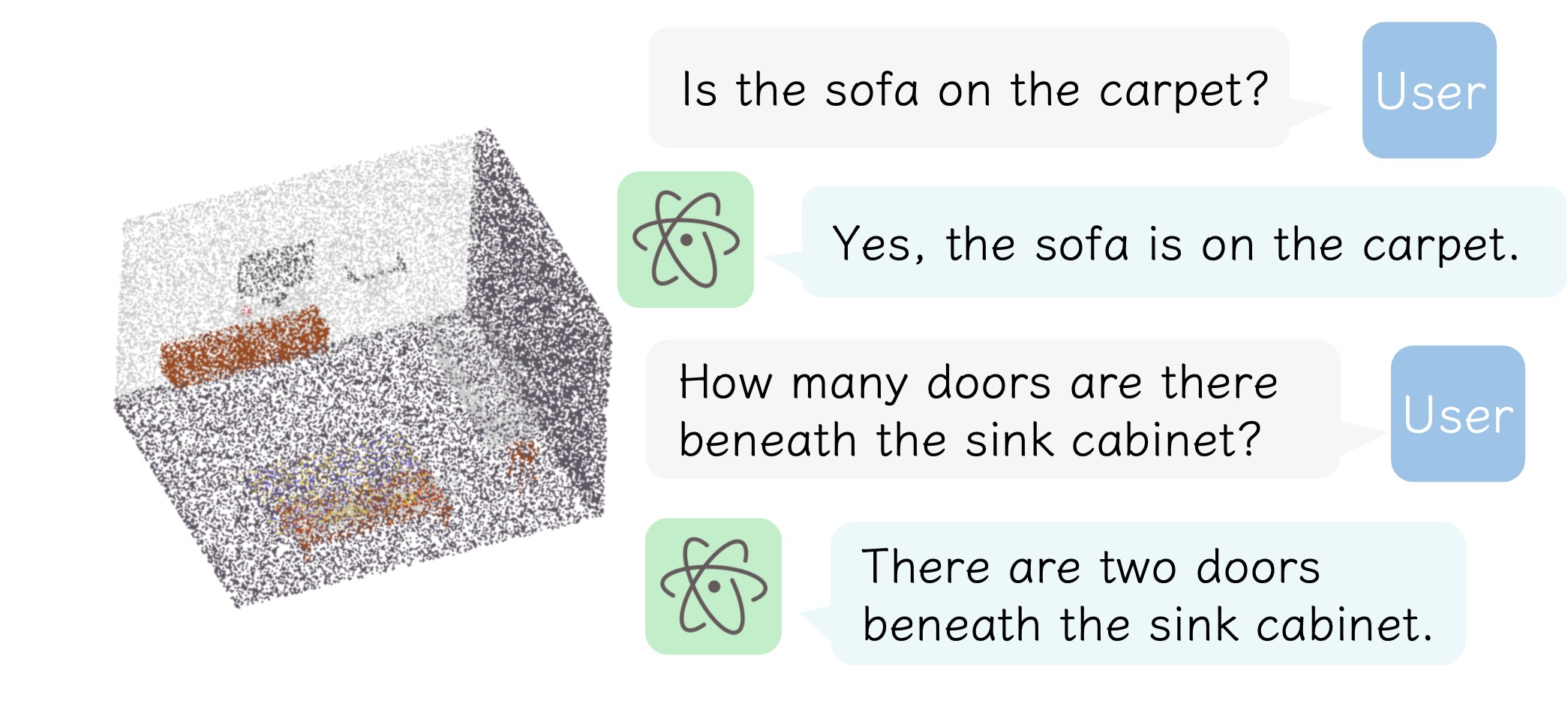
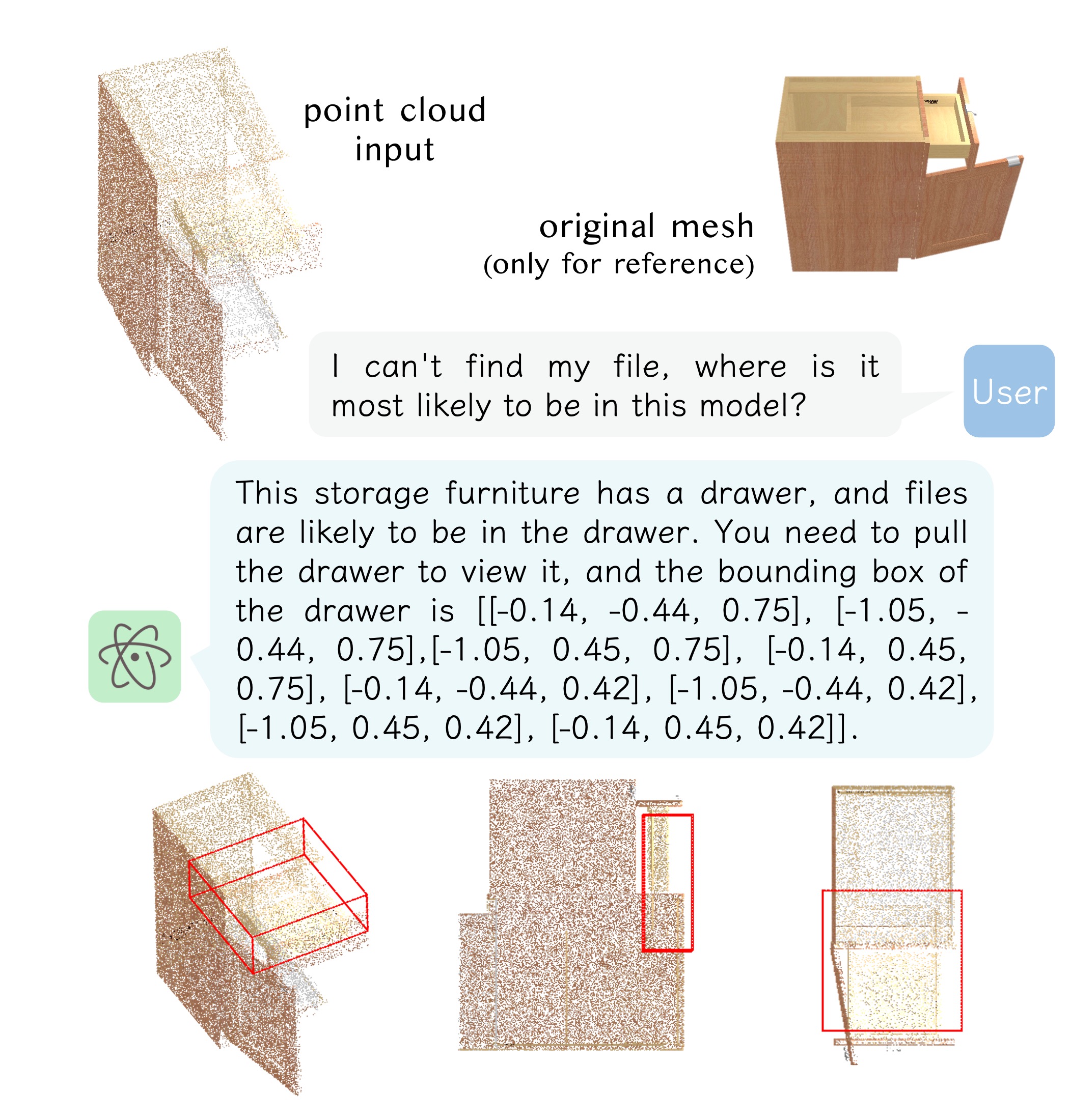
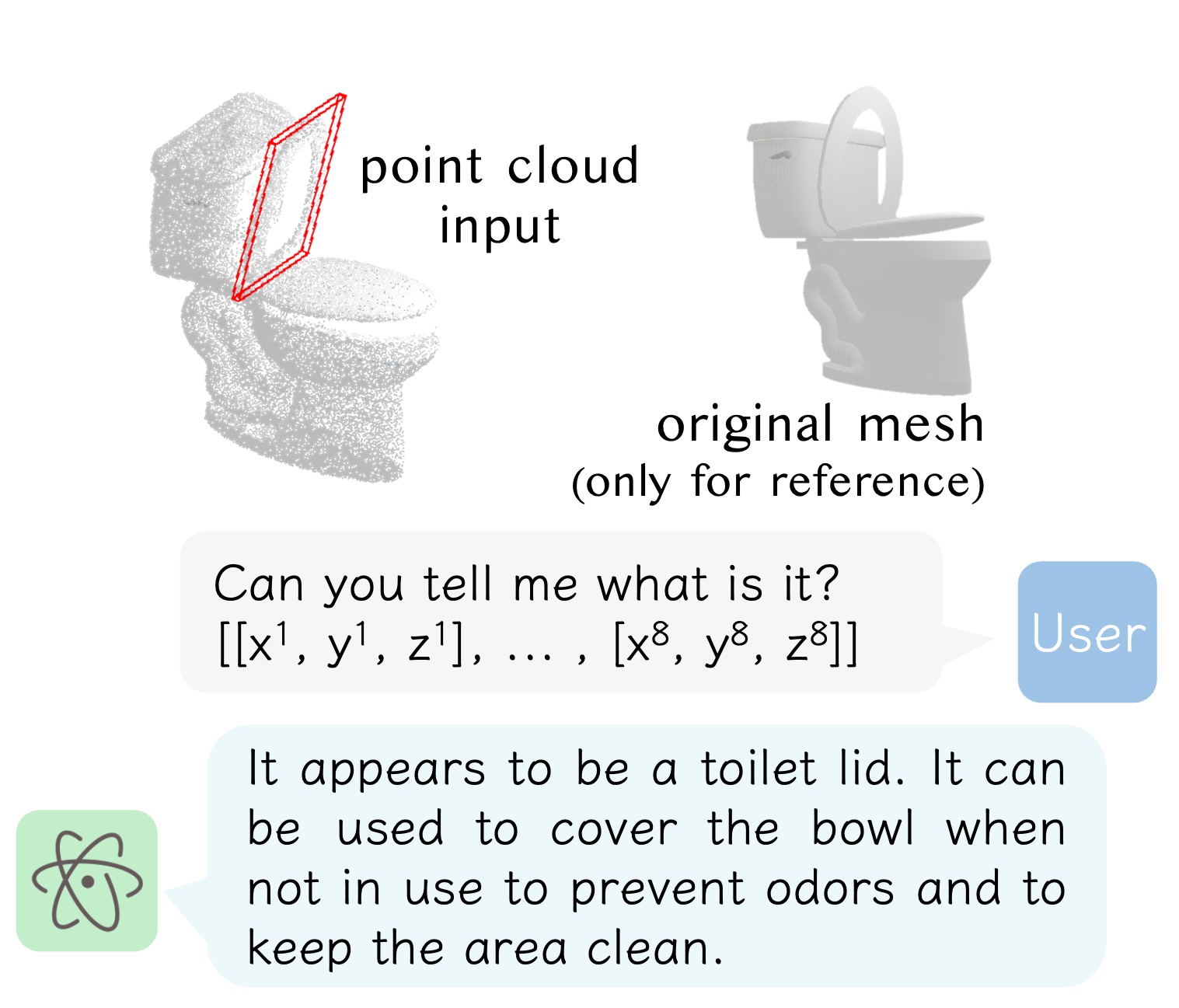
Pipeline






@article{qi2024shapellm,
author = {Qi, Zekun and Dong, Runpei and Zhang, Shaochen and Geng, Haoran and Han, Chunrui and Ge, Zheng and Wang, He and Yi, Li and Ma, Kaisheng},
title = {ShapeLLM: Universal 3D Object Understanding for Embodied Interaction},
journal = {arXiv preprint arXiv:2402.17766},
year = {2024},
}