Pipeline
S
h
a
p
e
L
L
M
Universal 3D Object Understanding for Embodied Interaction
ECCV 2024
What makes better 3D representations that bridge language models and interaction-oriented 3D object understanding?
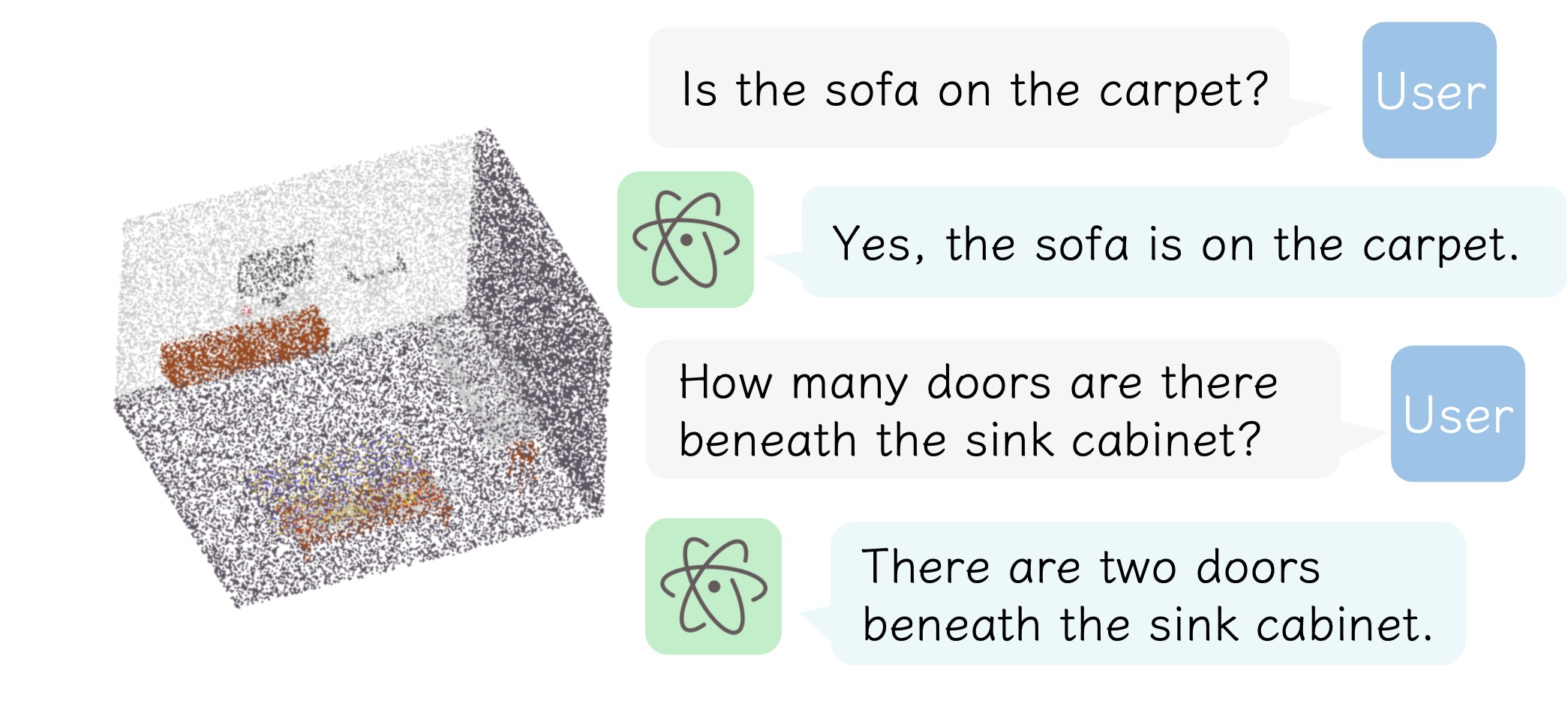
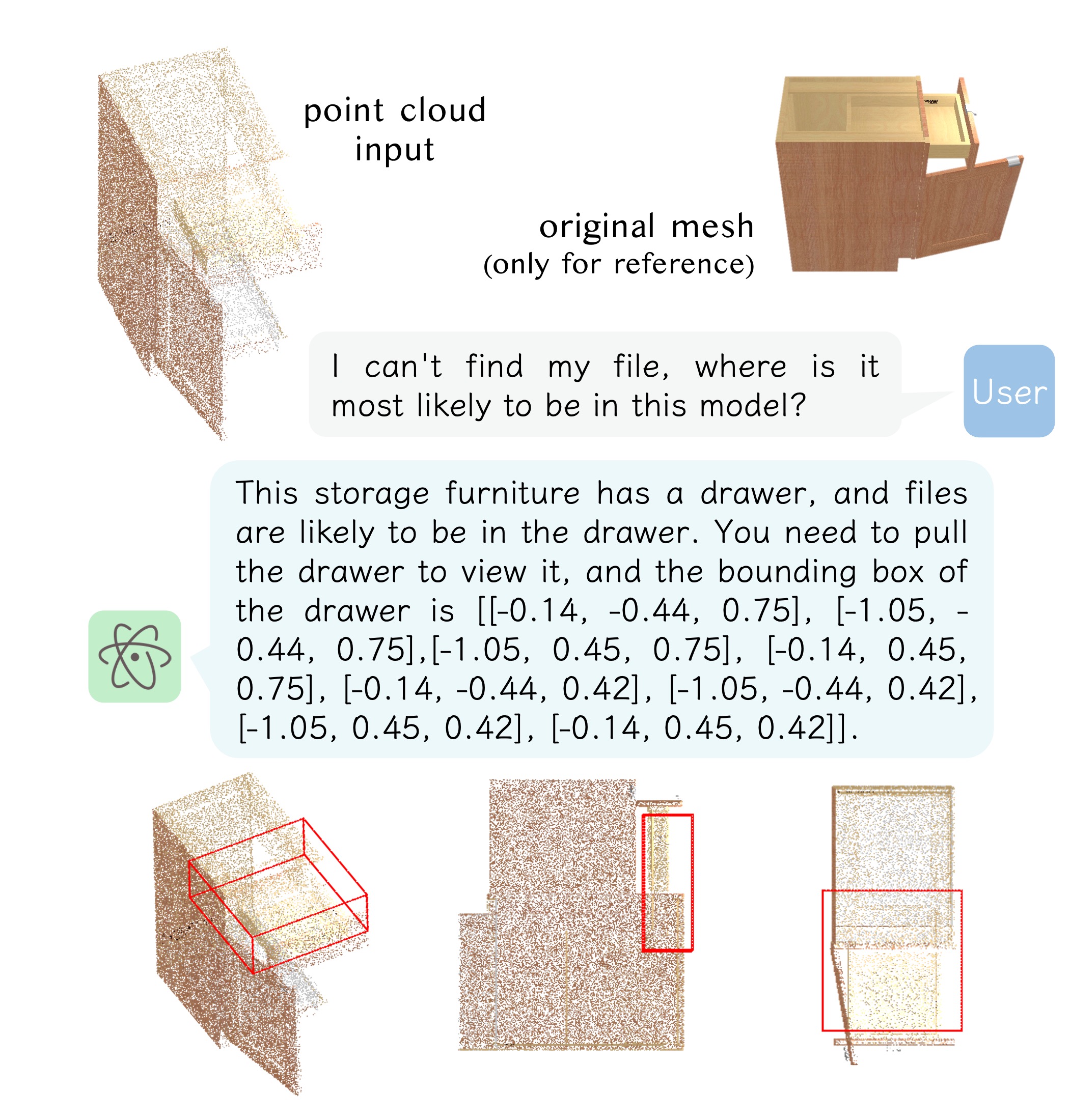
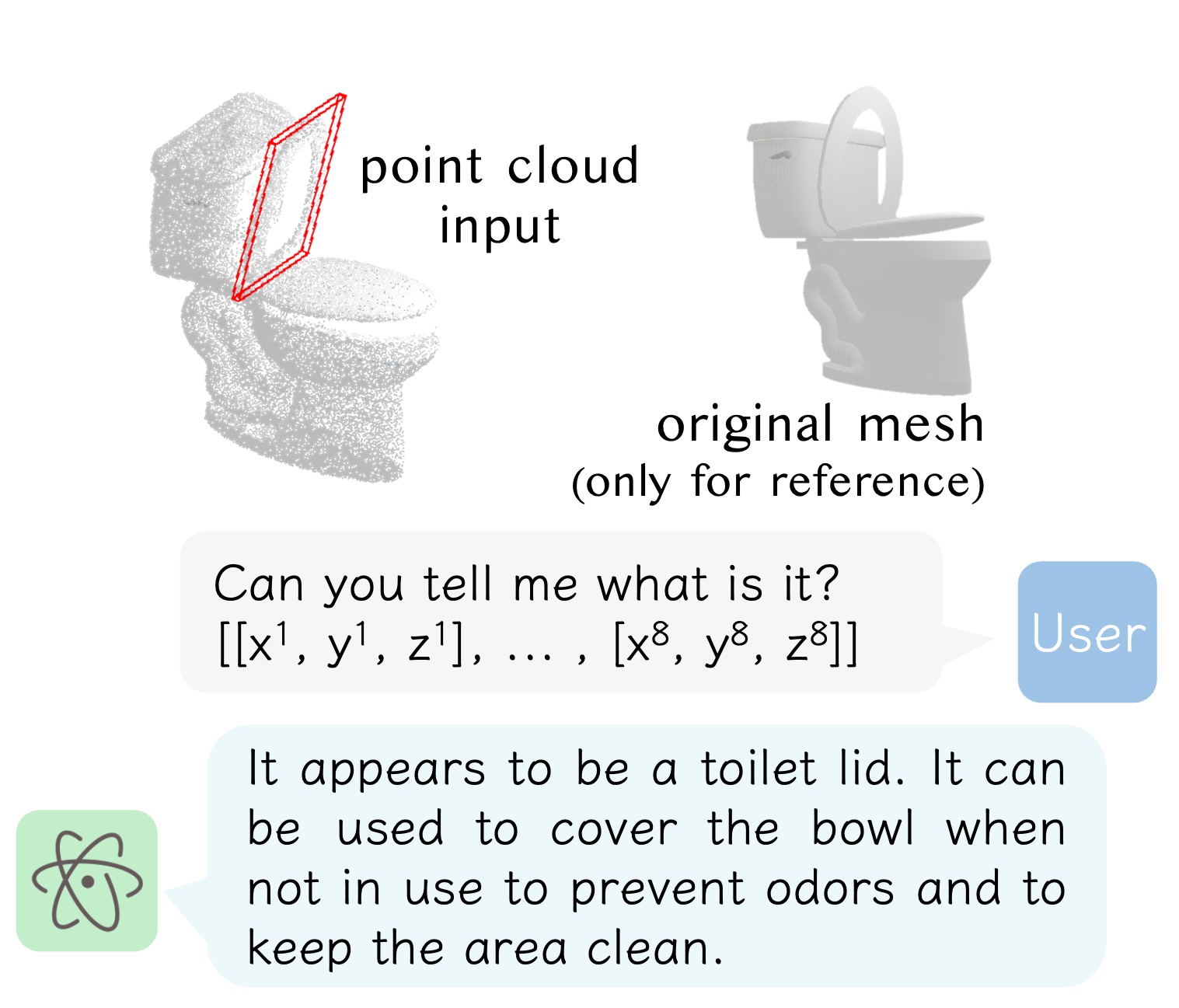
*Conversations generated with instructions provided by our users



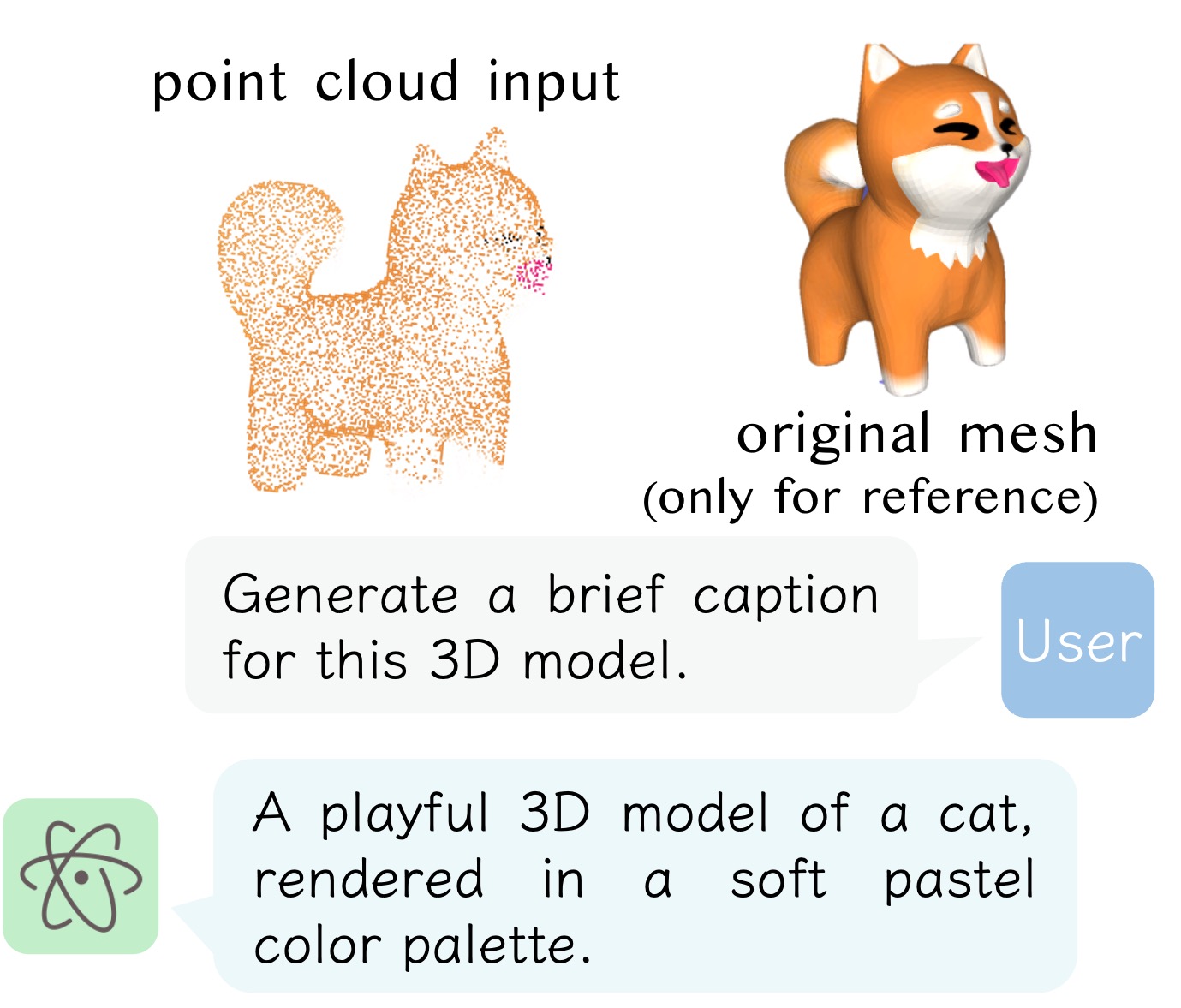

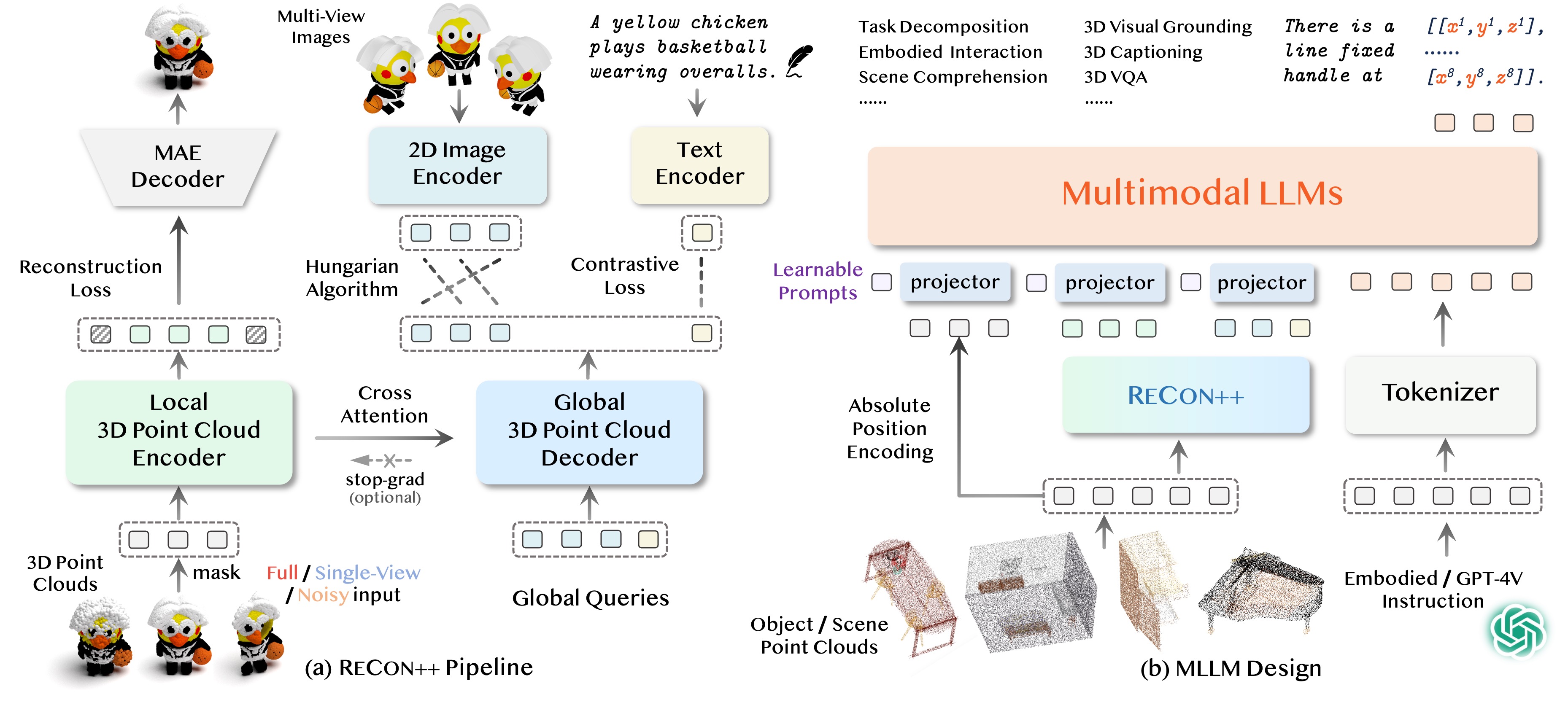
ReCon++ is a powerful point encoder architecture that achieves state-of-the-art performance across a range of representation learning tasks: Fine-tuned 3D recognition, Few-shot 3D recognition, and Zero-shot 3D recognition.

3D MM-Vet is the first 3D multimodal comprehension evaluation benchmark, which includes five different levels of tasks.

@article{qi2024shapellm,
author = {Qi, Zekun and Dong, Runpei and Zhang, Shaochen and Geng, Haoran and Han, Chunrui and Ge, Zheng and Yi, Li and Ma, Kaisheng},
title = {ShapeLLM: Universal 3D Object Understanding for Embodied Interaction},
journal = {arXiv preprint arXiv:2402.17766},
year = {2024},
}