
2026
We introduce Humanoid-GPT, a GPT-style Transformer trained on a billion-scale motion corpus for whole-body control, achieving zero-shot generalization to unseen motions and control tasks.
We present LATENT, a framework that learns athletic humanoid tennis skills from imperfect human motion data, enabling the Unitree G1 robot to sustain multi-shot rallies with human players.
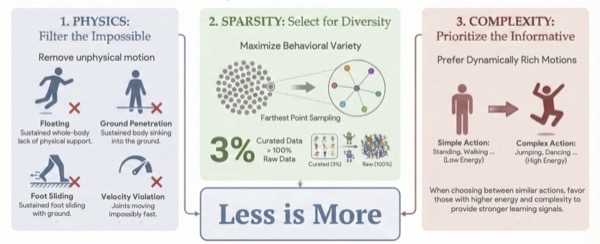
We introduce LIMMT, a data-centric framework for humanoid motion tracking that curates motion data through physics feasibility, action diversity, and action complexity.
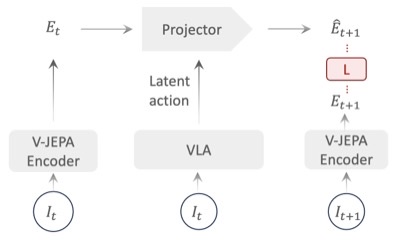
We introduce VLA-JEPA, a JEPA-style pretraining framework that learns action-relevant transition semantics by predicting future latent states, achieving consistent gains in sample efficiency and generalization.
We present MM-Nav a multi-view VLA system with 360° perception. The model is trained on large-scale expert navigation data collected from multiple reinforcement learning agents.

We introduce ReWorld, a framework that employs reinforcement learning to align video-based embodied world models with physical realism, task completion capability, embodiment plausibility and visual quality.
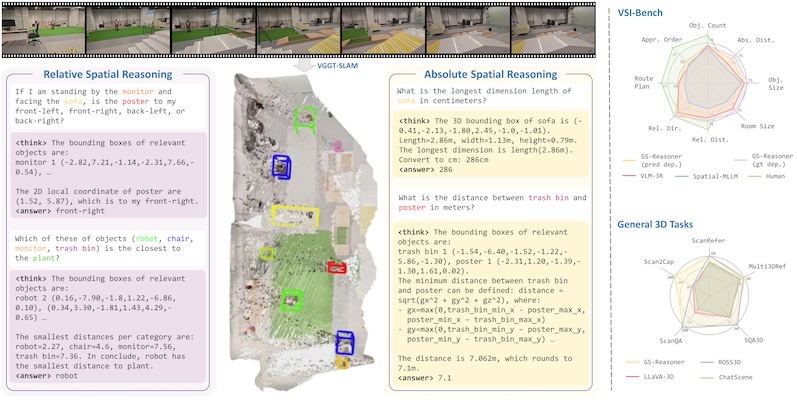
We believe that grounding can be seen as a chain-of-thought for spatial reasoning. Based on this, we achieve a new SOTA performance on VSI-Bench.
Based on cognitive psychology, we introduce a comprehensive and complex spatial reasoning benchmark, including 50 detailed categories and 1.5K manual labeled QA pairs.
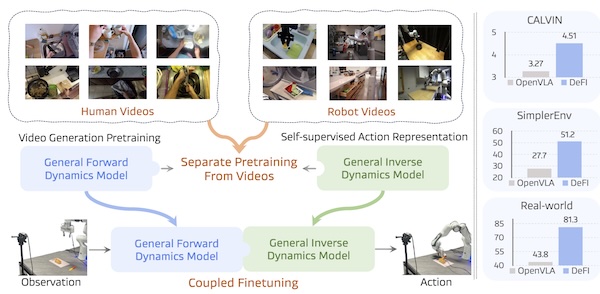
We propose DeFI, decoupling visual forward and inverse dynamics pretraining with a General Forward Dynamics Model (GFDM) for future prediction and a General Inverse Dynamics Model (GIDM) for latent actions from video, then unified finetuning for robot manipulation.

We present Switch-JustDance, a low-cost benchmarking pipeline that leverages Just Dance on Nintendo Switch to evaluate humanoid whole-body control, enabling direct human-robot comparison.
2025
We introduce the concept of semantic orientation, representing the object orientation condition on open vocabulary language.
We recast the vision–language–action model as a perception–prediction–action model and make the model explicitly predict a compact set of dynamic, spatial and high-level semantic information.
We introduce DexVLG, a vision‑language‑grasp model trained on the 170M‑pose, 174k‑object dataset that can generate instruction‑aligned dexterous grasp poses.
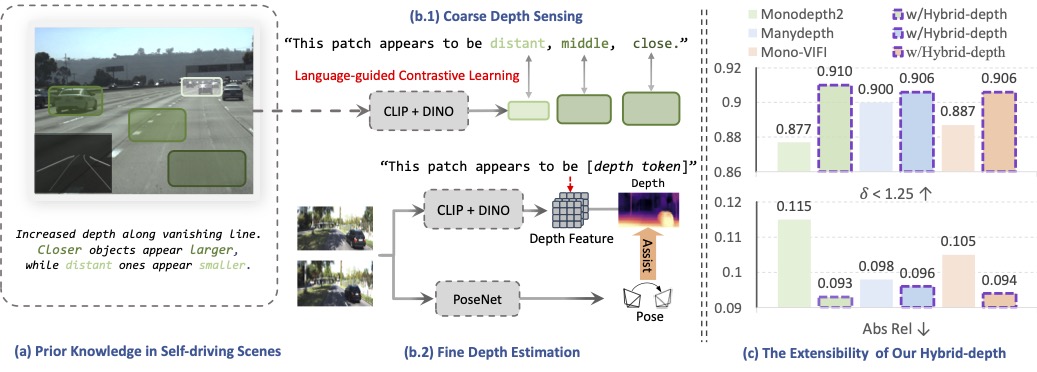
We introduce Hybrid‑depth, a self‑supervised method that aligns hybrid semantics via language guided fusion, achieving SOTA accuracy on KITTI.

We collect diverse images and prompts, and utilize GPT-4o for automated evaluation aligned with human preference.
2024
We present ShapeLLM, the first 3D Multimodal Large Language Model designed for embodied interaction.
We present DreamLLM, a learning framework that first achieves versatile Multimodal Large Language Models.
2023
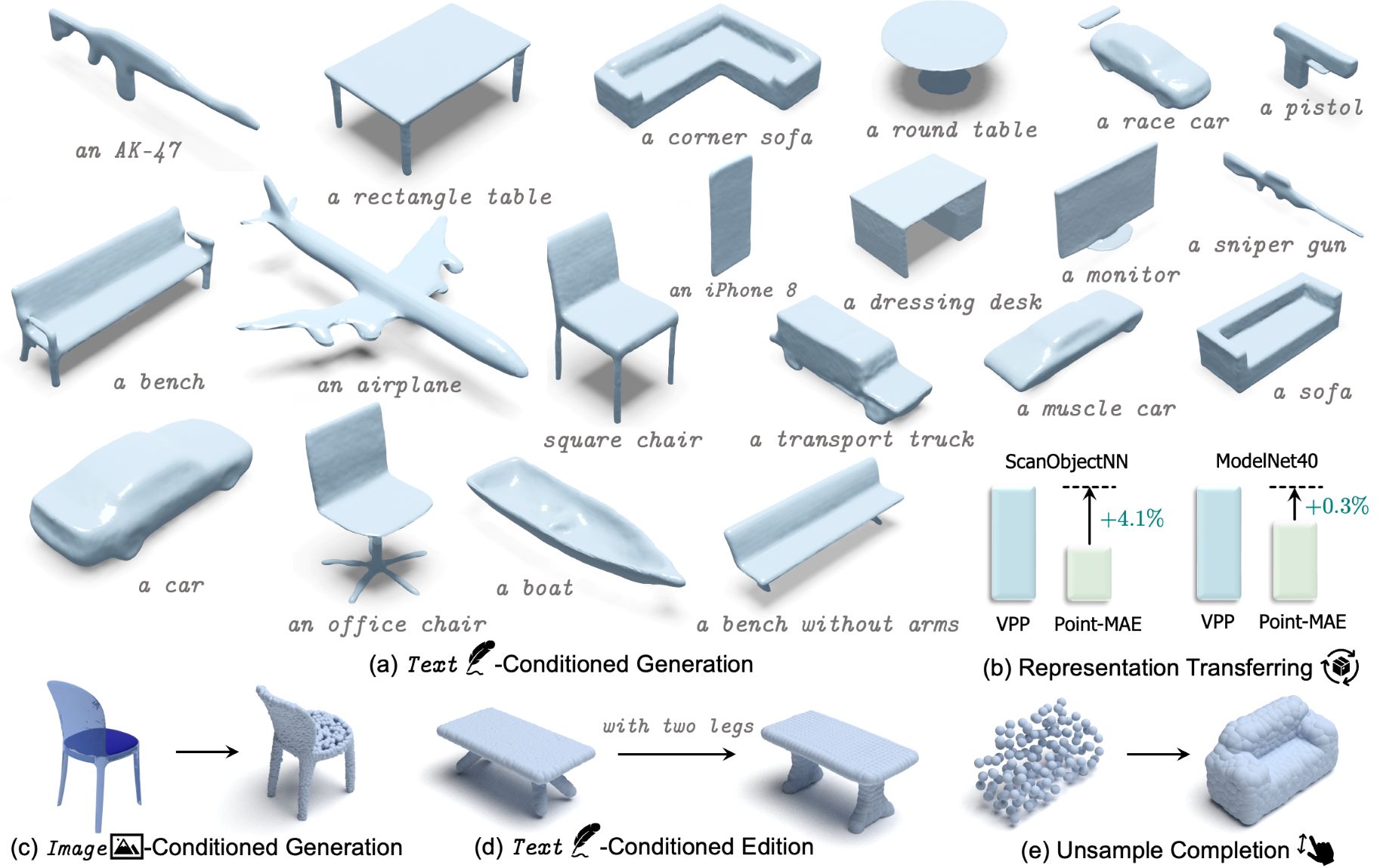
We achieve rapid, multi-category 3D conditional generation by sharing the merits of different representations. VPP can generate 3D shapes in less than 0.2s.
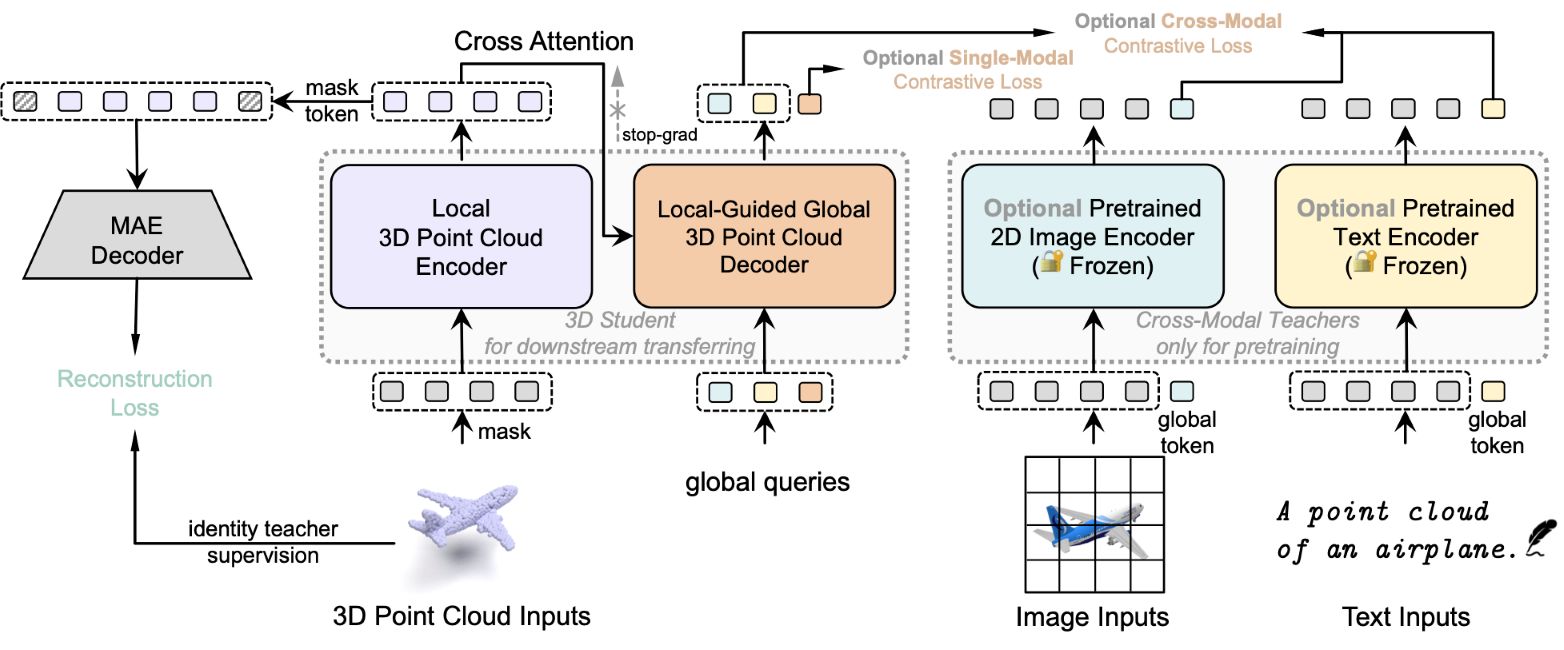
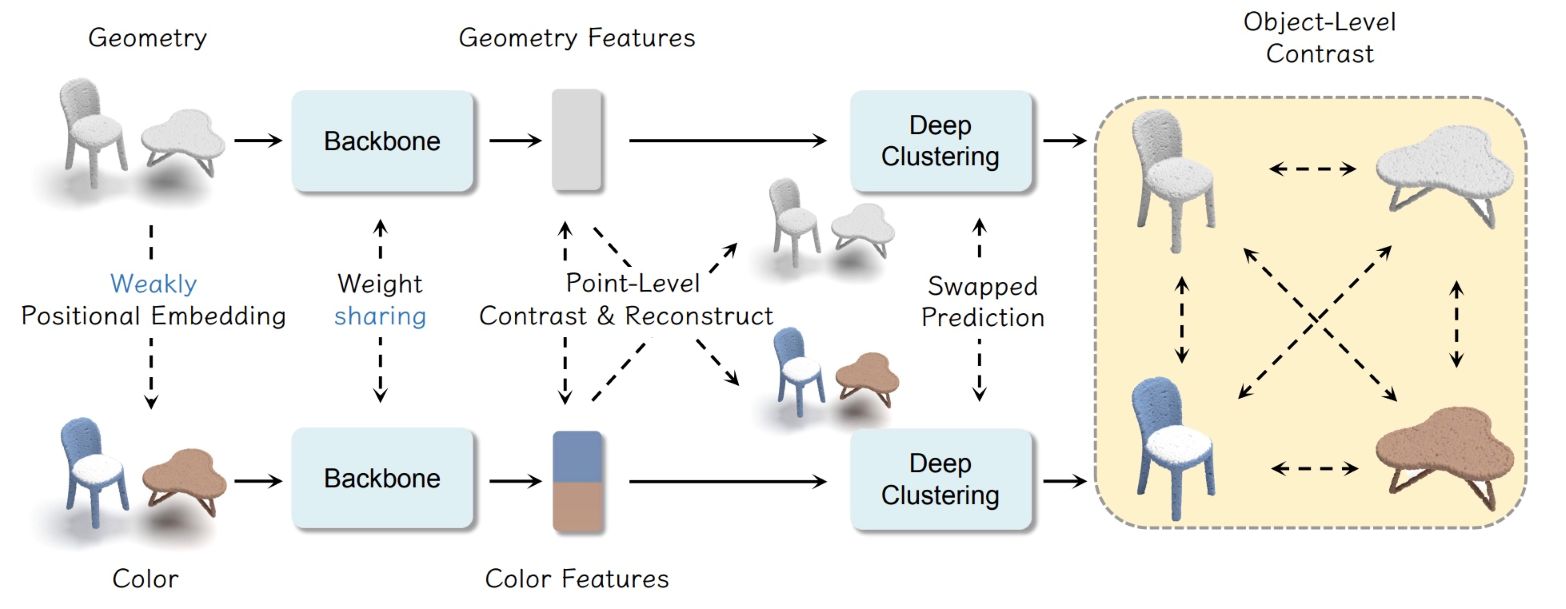
We propose contrast guided by reconstruct to mitigate the pattern differences between two self-supervised paradigms.
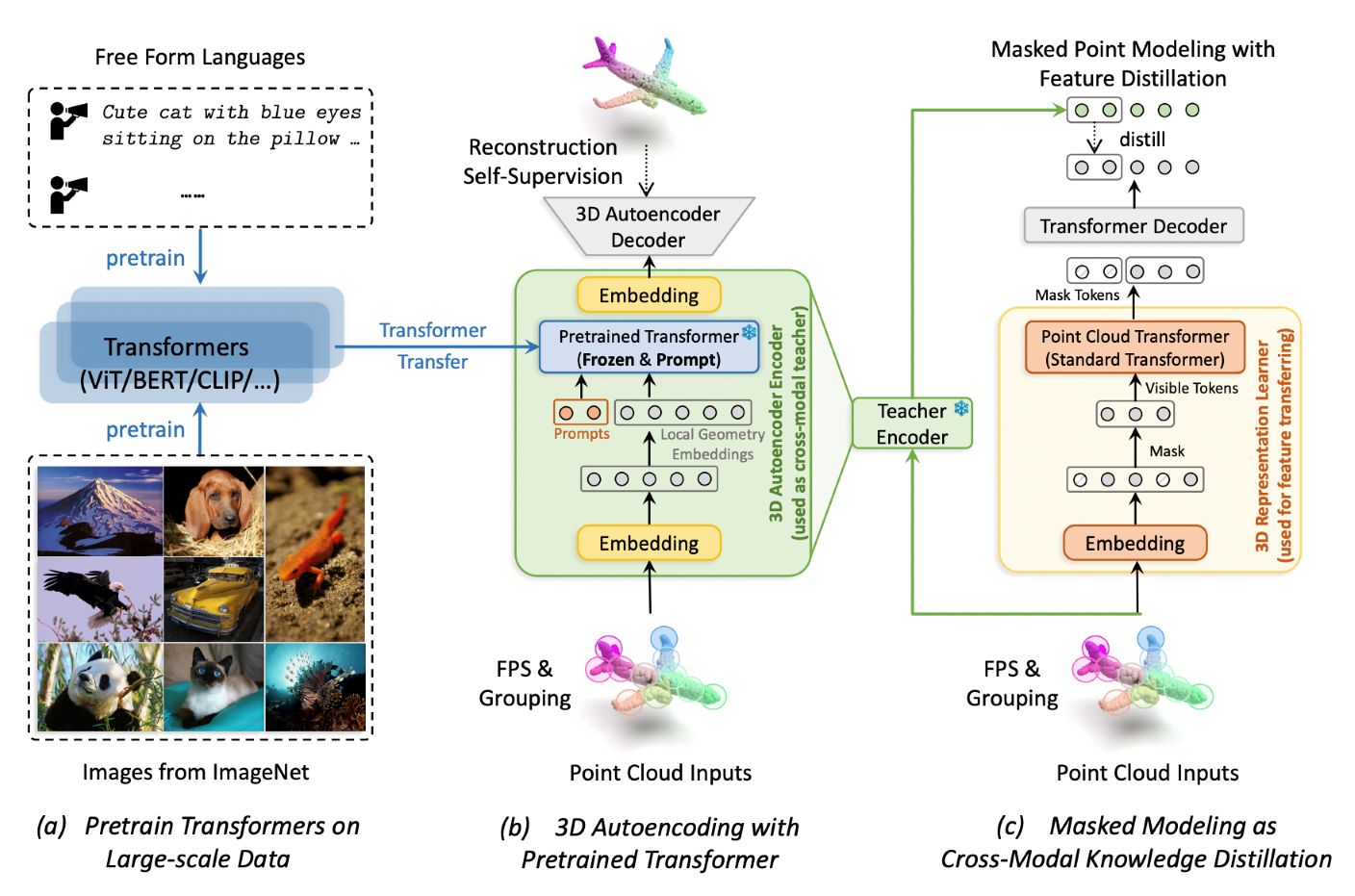
We propose to use autoencoders as cross-modal teachers to transfer dark knowledge into 3D representation learning.